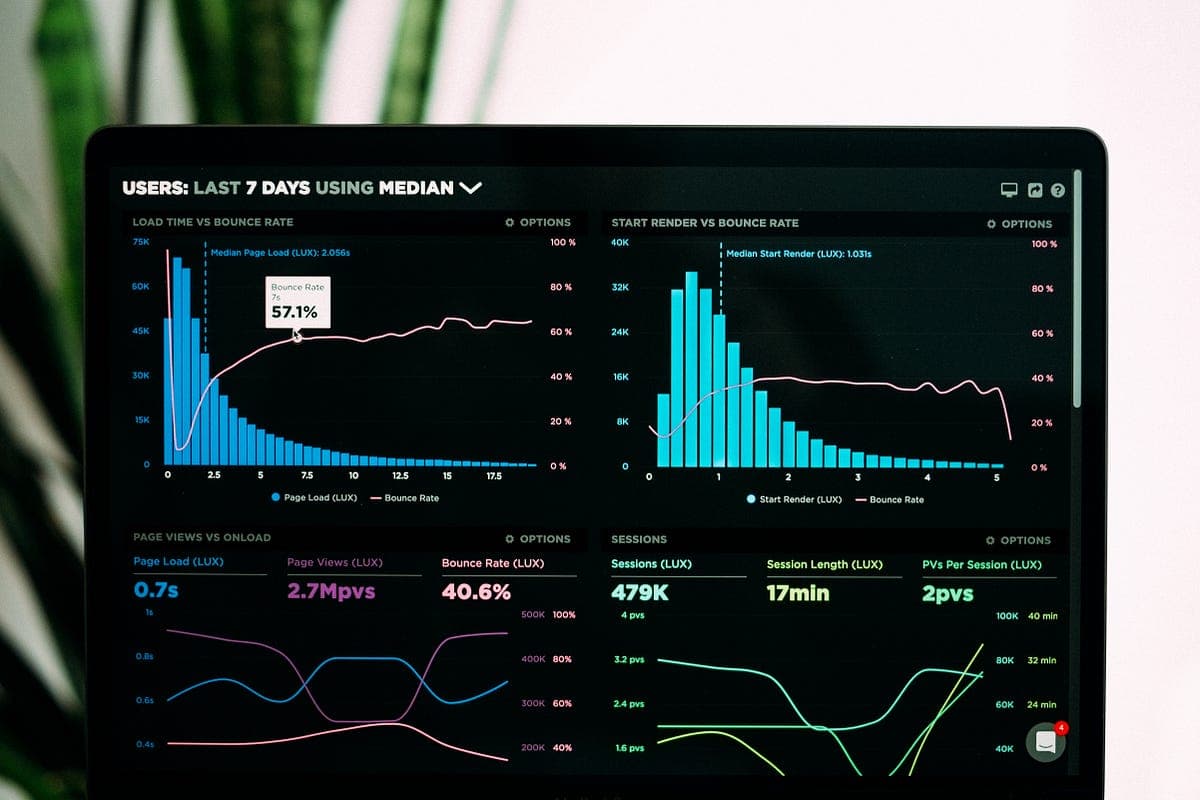
As a solutions architect at White Prompt, I’ve had the opportunity to delve deep into the intricacies of data management. Today, I’d like to share insights on a powerful tool that can revolutionize how we handle data lakes: AWS Lake Formation.
Understanding Data Lakes
A data lake is a centralized repository that allows you to store all your data, whether it’s structured or unstructured, in its raw form. This flexibility means you can dump any type of data into a data lake without the need for prior treatment or validation. The beauty of a data lake lies in its ability to centralize data, making it accessible from a single location, which is crucial for efficient data management and analytics.
The Challenges of Traditional Data Lakes
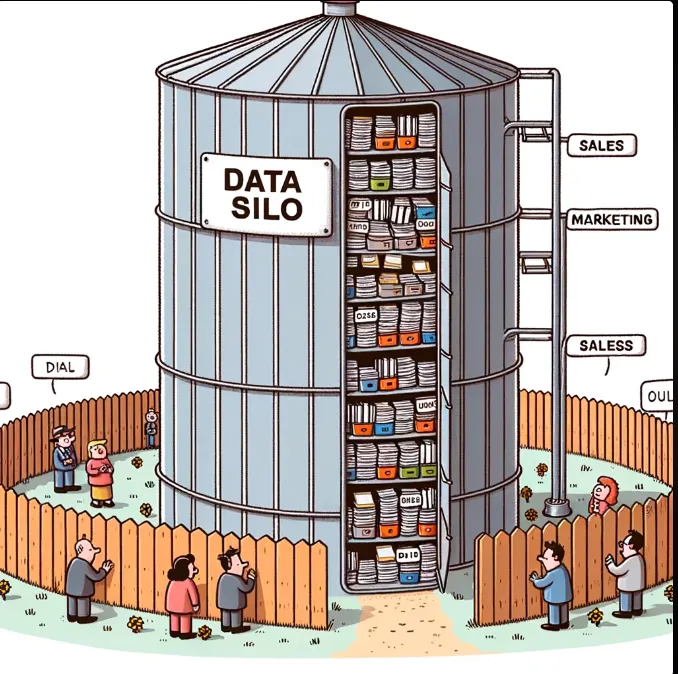
While data lakes offer significant benefits, they are not without challenges. One major issue is the occurrence of data silos, where data is stored in isolated repositories without effective communication between them. This fragmentation can lead to inefficiencies, inconsistencies, and a lack of a unified view of data across the organization.
Security is another critical concern. Without robust measures, sensitive information can be exposed to unauthorized users, leading to potential data breaches. Managing a data lake also involves handling the ingestion, cataloging, and quality control of data, which can become cumbersome without proper tools.
Additionally, setting up and maintaining a data lake involves technical complexity and can require specialized skills, leading to longer setup times and higher costs.
Enter AWS Lake Formation
AWS Lake Formation is designed to address these challenges head-on. It’s a fully managed service that simplifies and automates many of the manual steps required to create and manage a data lake. This includes collecting, cleansing, and cataloging data, which helps overcome data silos and enhances security through built-in AWS security features.
Key Features of AWS Lake Formation
Data Sharing: Lake Formation allows granular control over data sharing, down to the column level. This enables different teams to work with the same data set in different ways, promoting collaboration and reducing data management overhead.
Automated Data Management: With features like automated data discovery, cleansing, and cataloging, Lake Formation simplifies the data management process. This not only improves data quality but also reduces the complexity and time required to set up and maintain a data lake.
Integration with AWS Services: Lake Formation integrates seamlessly with various AWS services such as Amazon S3, Athena, EMR, DynamoDB, SageMaker, Redshift, and Elasticsearch. This creates a robust and flexible environment for data storage, analytics, and machine learning.
Cost Efficiency: The service is designed to be cost-effective. For example, most costs associated with using Lake Formation are minimal, with significant expenses typically arising only from additional services like Glue for data discovery.
Conclusion
AWS Lake Formation streamlines the process of setting up and managing data lakes, addressing common challenges like data silos and security concerns. By automating many manual steps, it not only simplifies data management but also fosters a collaborative environment through easy data sharing and discovery. For modern organizations looking to leverage their data assets effectively, AWS Lake Formation emerges as a valuable resource.
At White Prompt, we’ve seen firsthand how AWS Lake Formation can transform data management processes, making them more efficient and secure. If you’re looking to optimize your data lakes, consider exploring AWS Lake Formation as your go-to solution.