Introduction
Use the RECURSIVE functionality to create graph queries in relational databases using the CTE syntax ( Recursive Common Table Expression ).
To better illustrate the functionality I will provide some practical examples to perform recursive queries using traditional DBMS modelings such as ForeignKeys and Many-to-Many relationships.
The big advantage of this approach is that it allows us to model hierarchical relationships — graph models — in a relational database, with good query performance, saving us from the complexity of having a second graph-oriented database.
What are we going to build?
We recently had to implement a large database with a complex relational design. My initial estimation is around 75 million rows in the largest table. The client specification requires some graph queries to build paths traversing between relationships using many-to-many tables.
Usually, relational databases have serious performance problems for executing these types of queries through recursive code functions. Normally we move the data out of the database using a side process to export and create the nodes and edges in a graph database, requiring a lot of effort to keep the data synchronized with the master source.
Many times we only need to know “friends of friends” ( analogy to the social networks), for just a simple query we need to maintain this entire structure.
Postgres offers the RECURSIVE query which will bring the same data as a Graph with a plus that we can use the standard SQL features as “like”, “join”, and “aggregations” and just introducing the recursive query as part of your code.
Roadmap
In this project, we are going to create a model representing a simple database system based on the sqlfiddle site to perform some queries.
We will use http://sqlfiddle.com/ ( select Postgres >=9.6 ) to run the examples and view the results. Feel free to use your own Postgres server.
Recursive Query
The recursive queries are useful in many situations such as querying hierarchical data like organizational structure, parental relationships, etc.
The following example illustrates the syntax of a recursive CTE:
A recursive CTE has three elements:
- Non-recursive term: a query that forms the base result set of the CTE structure.
- Recursive term: the query that joins with the non-recursive term using UNION.
- Termination check: the recursion stops when no rows are returned from the previous iteration. For this example, we are limiting n < 100.
PostgreSQL executes a recursive CTE in the following sequence:
- Execute the non-recursive term to create the base result set (R0).
- Execute recursive term with Ri as an input to return the result set Ri+1 as the output.
- Repeat step 2 until an empty set is returned. (termination check).
- Return the final result set that is a UNION of the results sets R0, R1, … Rn.
Hierarch Basic Data
In this section, I will present some real-world examples with functional code for table creations and query structures that you can copy and paste into sqlfiddle.com.
Trees
We created a table called PERSON who will receive the names of each participant, their salary, and who they are related to, which is an FK for the table itself.
The self-relationship is used to create algorithms in the form of a tree that follows a pre-defined hierarch.
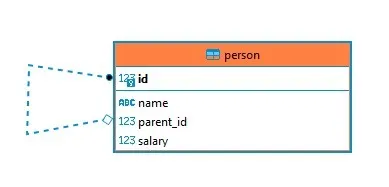
It’s a basic concept, but we can navigate this structure in several ways. For example:
- Returns the path between Manuel and Oscar
- All _PERSON_below Anderson, who earn more than 50k
- What is the distance between points A and D
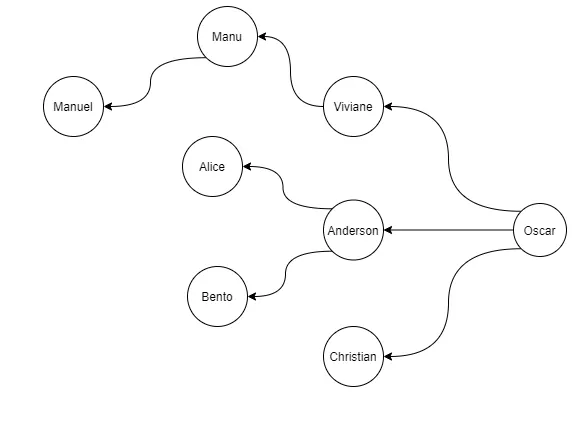
Get manager hierarchy from an employee:
After creating the temporary table “hierarch” using WITH becomes easy to play with the result:
Replace the “SELECT * FROM hierarch;” for the code below to display the data in a user-friendly result:
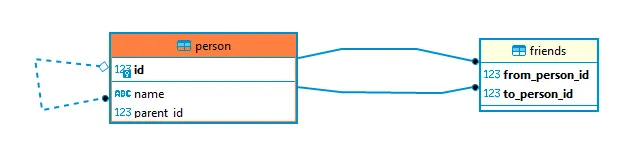
Graph
In this example, I created a many-to-many lookup table to relate FRIENDS. This schema allows us to create the path of all relationships that exist in this table, referring to the “Friends of Friends” functionality.
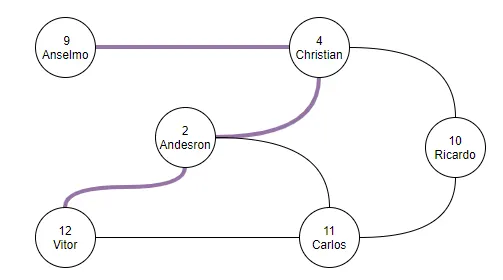
Usually, the graph algorithms help us to calculate the distance or path between the point 9 to 12 following the example above:
Briefing about Postgres Array:
- Definition: ARRAY[1, 2]
- Concatenate: ARRAY[1, 2] || ARRAY[3] = [1, 2, 3]
- ALL: find a value inside the ARRAY returning TRUE or FALSE
- UNNEST: expand an array to a set of rows
Build the Friends of Friends graph
You can filter for a specific FRIEND in the non-recursive query using WHERE (advisable) OR allow it to be filtered later in the temporary table (heavy solution).
To apply the limits, add a simple WHERE clause to the non-recursive term:
Following the example that explains how to limit the path using the temporary table by START and TARGET:
A query without limits can generate a database overload, ideally, always limit the depth that you are looking for the relationships.
Benchmark
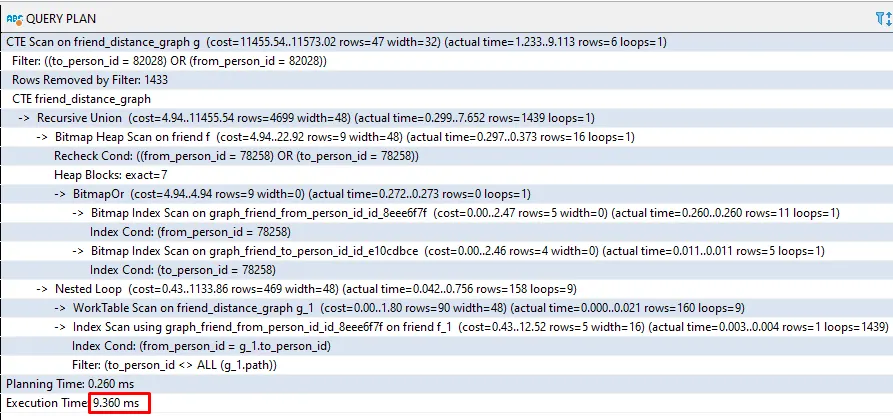
To prove the concept using the same model, I developed a routine to insert 2Mi rows in the PERSON table, followed by a random function to relate 5 FRIENDS per PERSON. Subsequently, the database must process the JOIN against 12Mi rows.
I randomly choose two PERSON (78258, 1807125) not connected by the FRIEND table running the simple query below:
Then I executed the recursive query to generate all possible paths between from_person_id=78258 to_person_id=1807125.
Simply change the final query to retrieve the shortest path from A to B adding the limit statement:
I ran the queries many times and the results are super fast varying from 9ms to 120ms and for the worst-case scenario, it takes 1 second to calculate the full path in a temporary table.
Wrap up and take-aways
If you are using a NoSQL like MongoDB, the recommendation is to perform a function to export the relations of your data to a Neo4J, Arangodb, or even Redis to support the graph queries.
With a simple query, we avoid rewriting an entire system. Of course, Graph databases can offer many other features. The main advantage is being able to do the basics within the same database, and this is adequate for a simple approach.
The performance of the recursive queries even running with 10 mi rows is pretty good, returning in a few milliseconds, comparable to the time taken for the database to execute a: IN( subquery ).
I don’t recommend using a relational database only for recursive queries. Many open-source solutions exist to handle the job using fewer resources. The presented solution avoids the data transfer between the database and other query engines.
We think, and we do
Do you have an application that requires graph queries in a relational database? Talk to us. We can help!
Further Reading / Links
https://www.postgresql.org/docs/9.1/queries-with.html https://www.geeksforgeeks.org/binary-tree-data-structure/ https://www.geeksforgeeks.org/graph-data-structure-and-algorithms/ https://www.alibabacloud.com/blog/postgresql-graph-search-practices---10-billion-scale-graph-with-millisecond-response_595039 https://www.postgresqltutorial.com/postgresql-union/
Photo by Pietro Jeng on Unsplash


